In a very simple setup, the app server/service talks to the database for the data. Data stores are disk-based with some frequently accessed data cached in the memory.
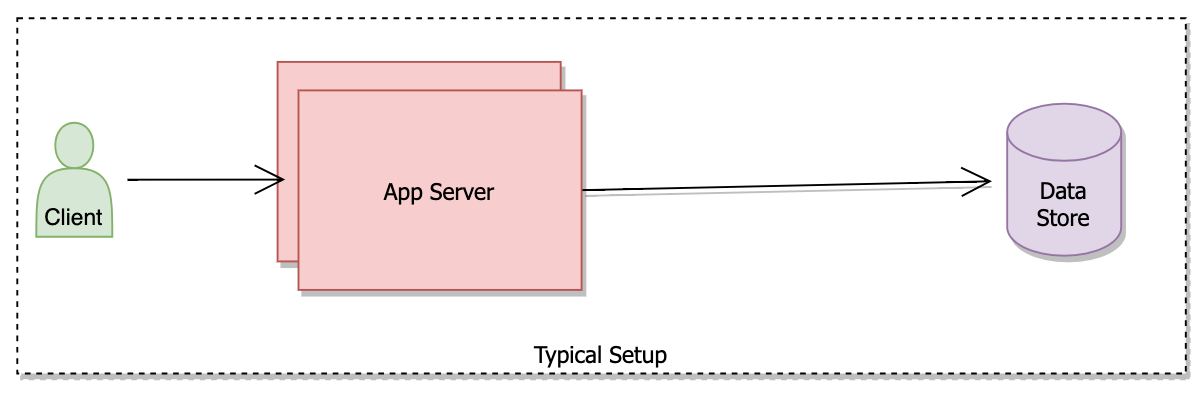
The benefit of the above setup –
- Less operational overhead because of its simplicity.
- Perfect setup for a low user base.
Drawbacks –
- With an increasing user base load on data stores will increase, resulting in bad read and write performance.
- In case of database failure, the whole system will stop working.
A typical strategy is to add a cache layer between the app server and the data store. A cache layer keeps frequently accessed data in memory hence improving the performance.
An internet-scale application with millions of users depends on cache heavily and they typically use Distributed cache system for high performance and scalability.
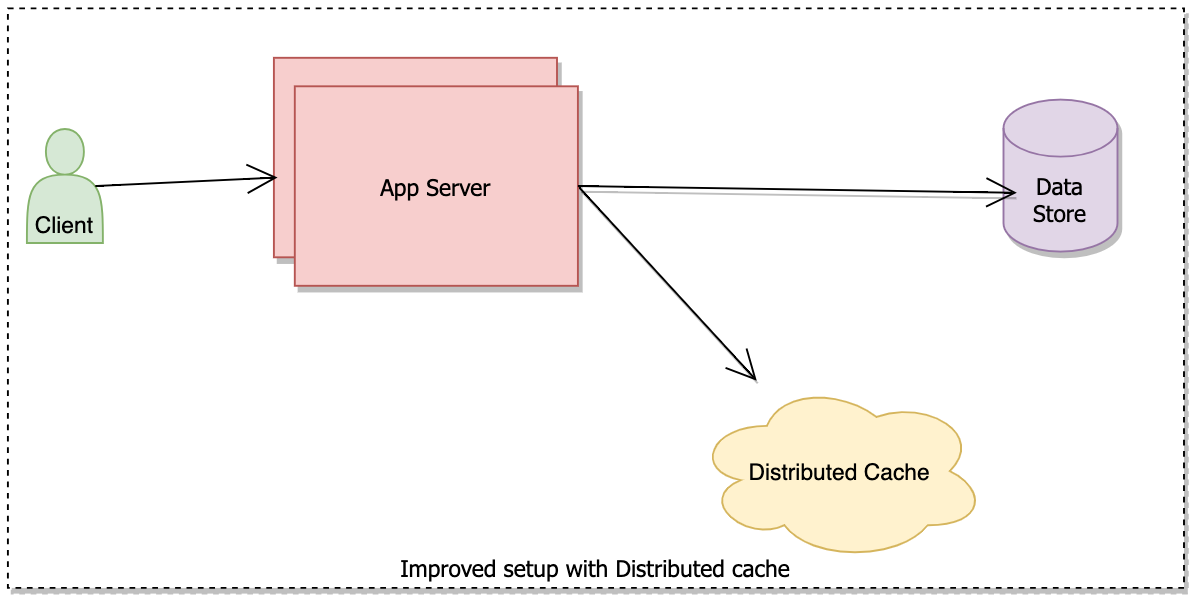
In the above system, the app server will check the data first in the cache, if found return the data, if not send the request to the Data Store.
Benefits of the above setup –
- Load on Database reduces, freeing resources, making it more reliable.
- Performance improvement as the cache is in memory and its data fetch time is faster than disk.
- Support for horizontal Scalability.
Drawbacks –
- Extra cost for operation for the distributed cache.
- Increased operational complexity.
Distributed cache requirement
In a cache system functionally we need two basic methods –
put(key, value)get(key)
Non-functional requirements of the cache systems are –
- High performance – Fast put and get method.
- Scalability – Ability to scale vertically as well as horizontally.
- High Availability – In case of failure and network partition it needs to work well.
Local cache
Before jumping on to distributed cache it’s better to understand what it will take to implement a local cache (e.g. within the app server itself) and then we can focus on expanding the solution in a distributed environment.
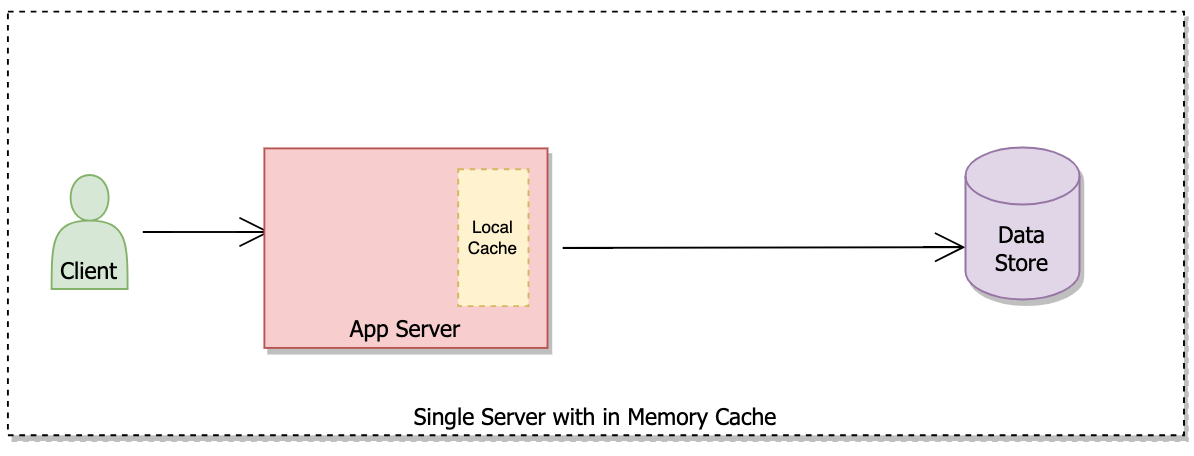
Local cache is an algorithmic problem and understanding how to implement it is important.
A simple approach is to use a HashTable to store key and value to achieve O(1) time complexity for get and put operations.
But we soon hit the max capacity of HashTable and need to evacuate old elements to add new ones.
There are several strategies for element evacuation from the cache and one of the widely used policies is the Least Recently Used (LRU) policy.
Cache Evacuation Policy – Cache evacuation policy is a strategy using which we remove an existing element from a cache to provide room for a new one. For e.g Least Recently Used (LRU), Least Frequently Used (LFU), First In First Out etc.
The least recently used cache implementation
As we can observe, Hash Table don’t track when an element is accessed. Hence we need another data structure to keep this data.
We can use Queue for tracking the Least Recently Used Item. Using a doubly linked list we can easily add a recently accessed element to the head and remove the least recently used item from the tail.
In the flowchart below we can see the algorithm required to implement the LRU cache.
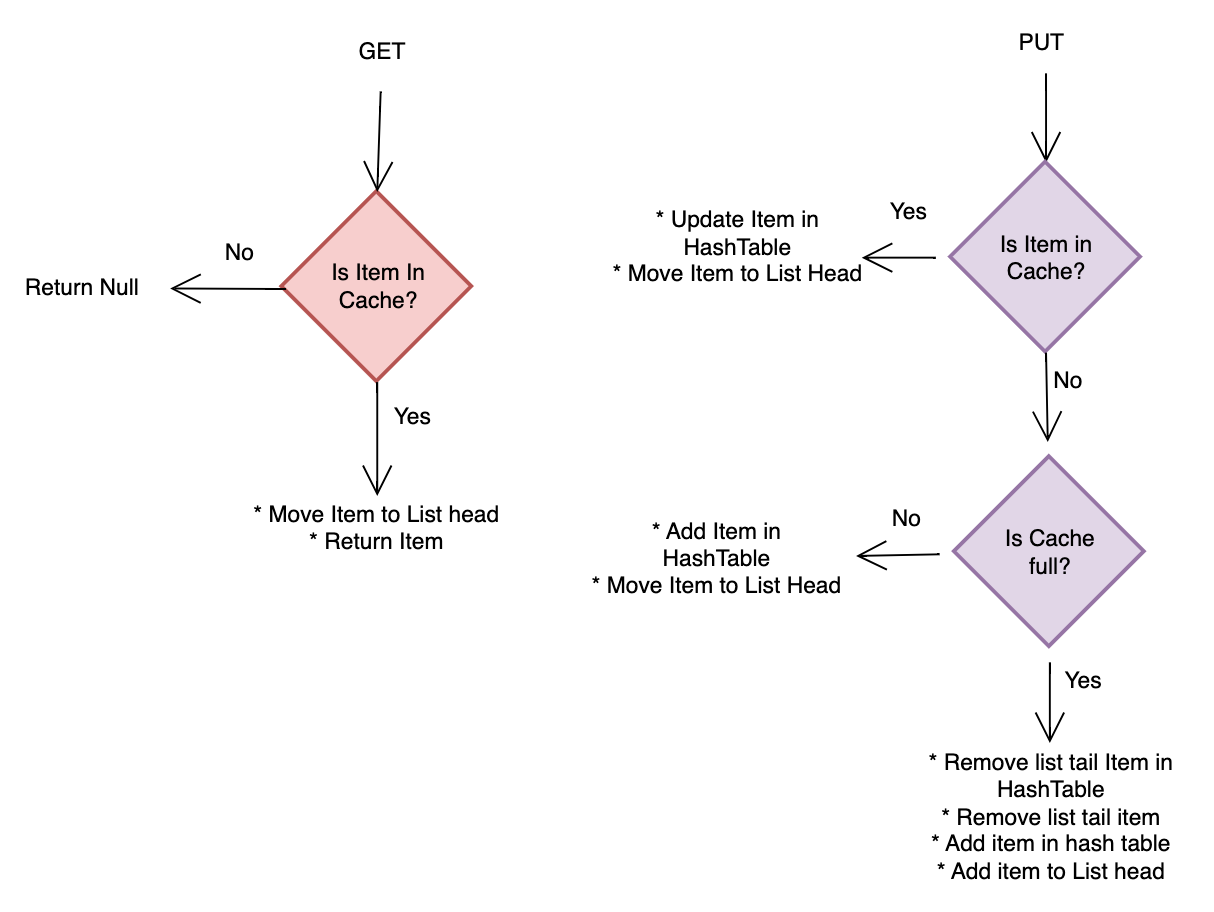
Benefits of local cache –
- It’s a very simple setup with no operational overhead.
Drawbacks –
- Lack of isolation between the app server and cache.
- Shared resources between the app server and cache result in low performance.
- We can’t scale the cache independently.
Distributed cache setup
To overcome local cache performance and scale limitations we can use a distributed cache system. Distributed cache system with many servers with each server handling a specific set of cache keys is a high-performance and scalable solution.
There are two different approaches to setup distributed cache –
- Cache cluster
- Co-Located cluster
Cache cluster approach
In a cache cluster setup, we have multiple shards in the cache cluster and the load is distributed on shards hosts based on the cache key. App Server with the help of a cache client knows about shards and sends requests accordingly. Cache clients use TCP / UDP protocol to communicate with each other.
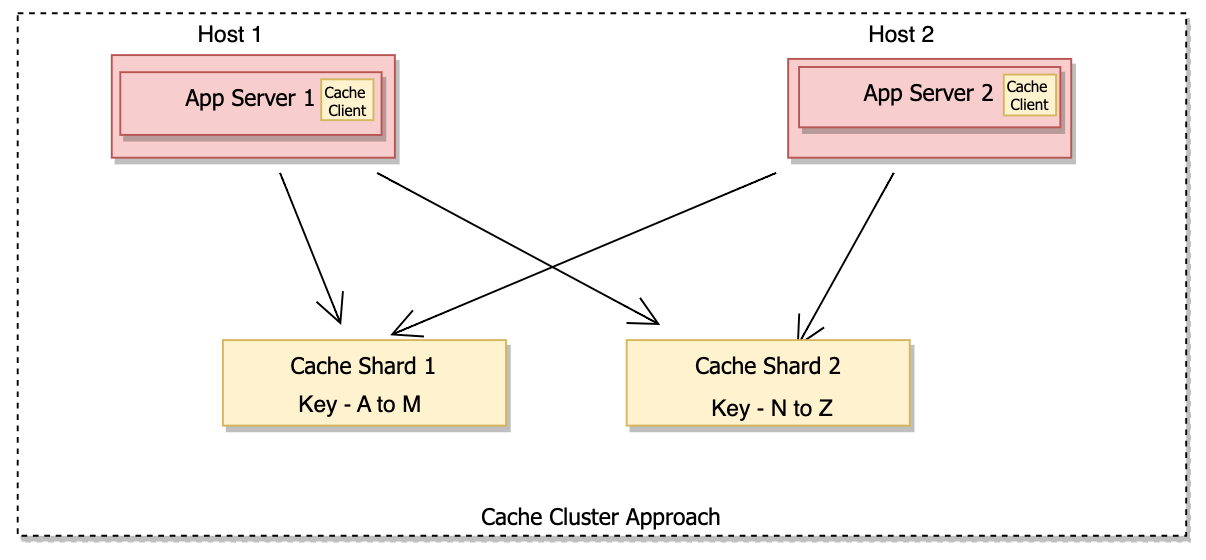
Benefits of cache cluster approach –
- Several partitions mean bigger capacity and better performance.
- Horizontally and vertically scalable.
- Ability to leverage custom hardware for each cache server.
Drawbacks –
- More servers mean more operational overhead.
Co-located cluster approach
In a co-located cluster approach cache server runs as a separate service on the same host (machine) as the app server.
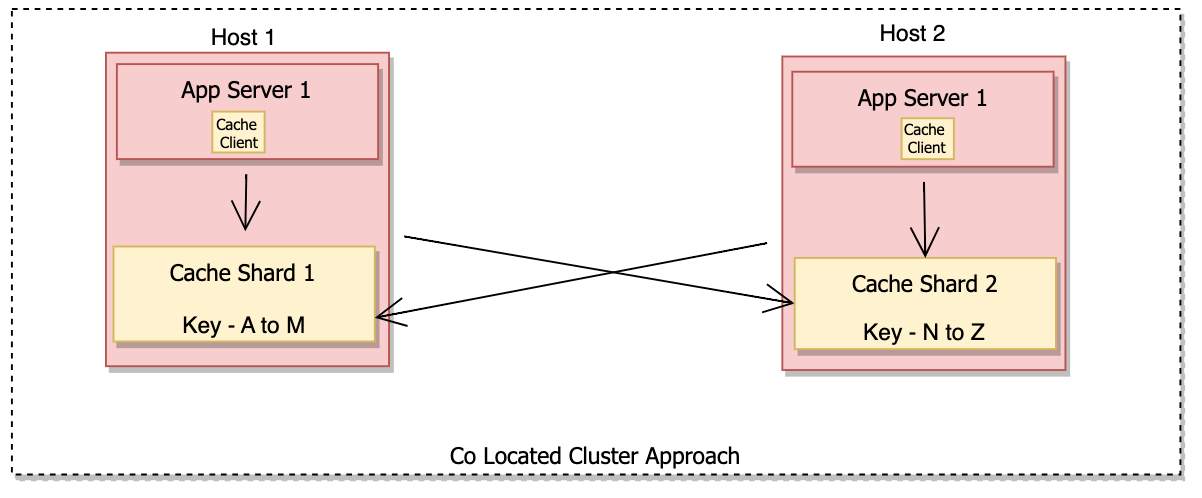
Benefits of this co-located cluster setup –
- No separate hardware is required.
- Less operational complexity.
- It scales with service.
Drawbacks –
- No isolation between the app server and the cache process.
- Cache scalability is limited to the scalability of the app server.
- We can’t configure special hardware for Cache.
Both of these setups are widely used, e.g. Memcache[1] in earlier days used a co-located cluster approach.
Cache server selection
How does a cache client choose a server for a specific cache key?
Cache clients can use various techniques like modulus hashing, consistent hashing or others to achieve that.
Modulus function
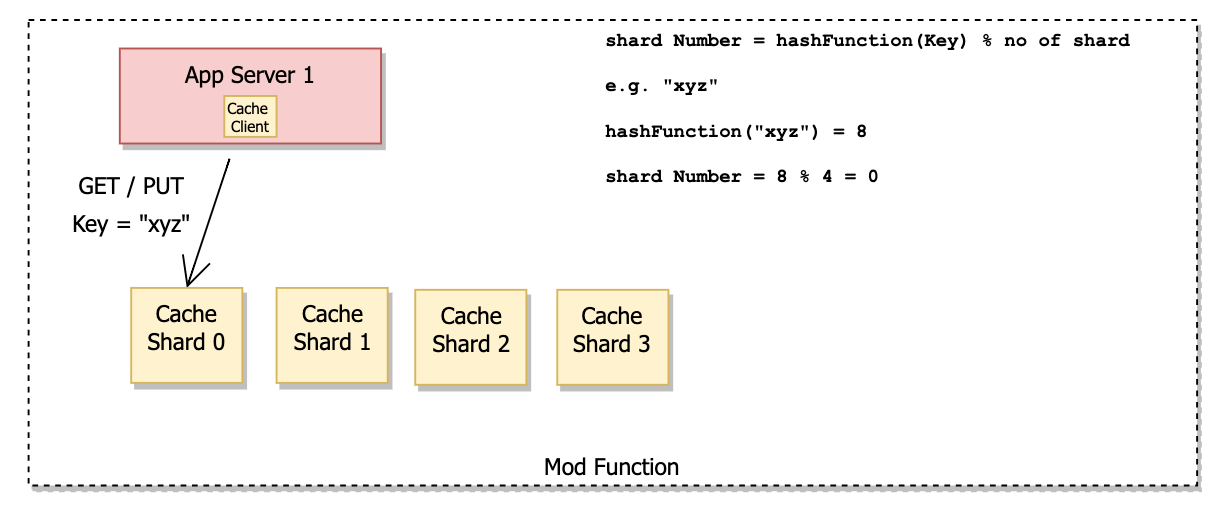
In the mod function approach, we find out the hash value of the key using a hash function. Then we find the shard number by calculating – hash value % no of servers (shard).
This approach works fine till we require adding and removing shards. As the number of shards changes, resharding changes the key to shard mapping for the majority of keys.
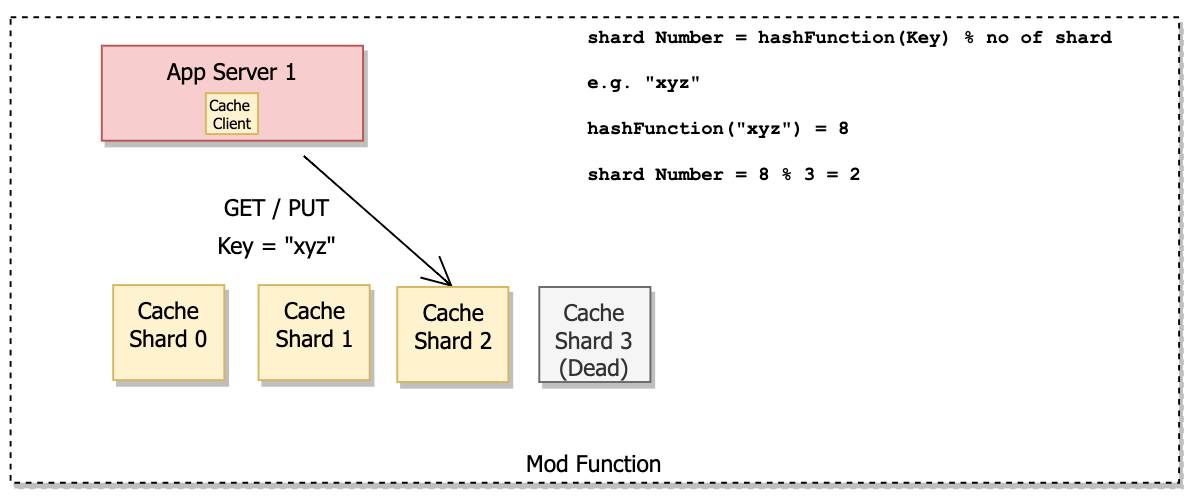
Benefits of mod function –
- Simple to implement the approach.
- Good for testing environments.
Drawback –
- Resharding leads to lots of cache misses due to changes in key-to-shard mapping.
For a dynamic environment where we add and remove servers frequently, the mod function is a bad idea.
Consistent Hashing
Consistent hashing tries to minimize the impact of cache misses when the number of servers changes by limiting the impacted keys.
In consistent hashing, we apply the hash function on servers and keys and their hash is mapped onto a hash space represented as a circle. To map a key to a server, we scan for the first server in a clockwise direction from the point of the key on the circle. When a server is added or removed (dead), resharding only impacts a few of the cache keys, which minimizes the data movement.
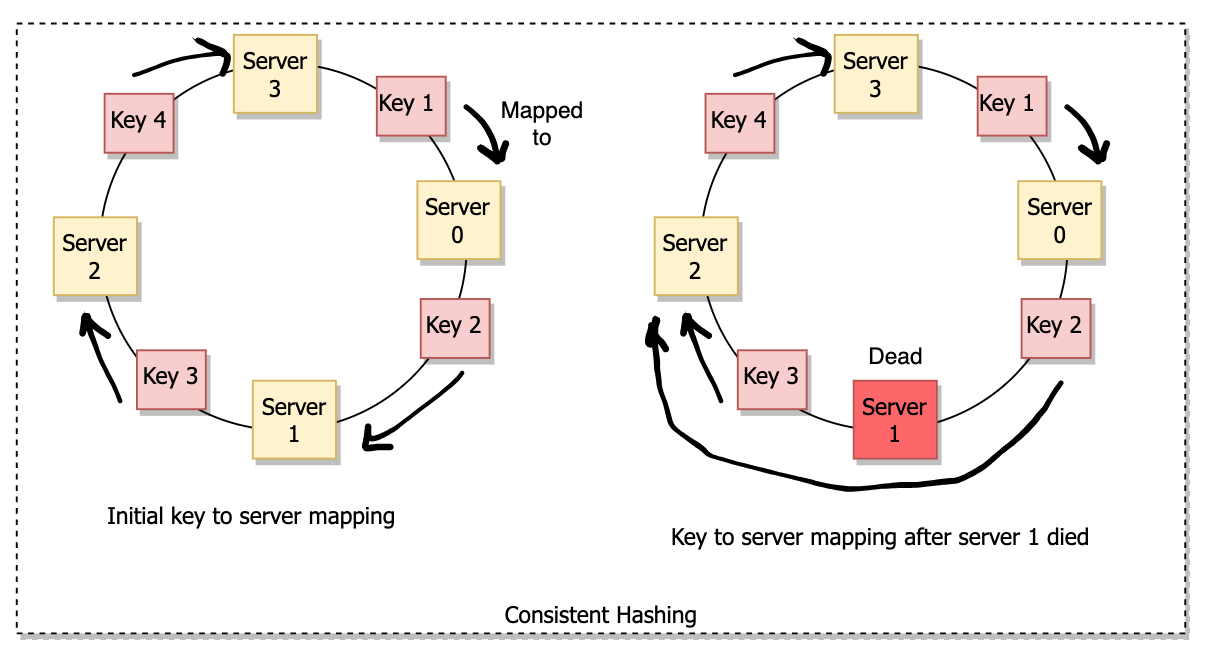
In comparison to the modulus function, consistent hashing is more efficient and handles the dynamic load.
Refer dedicated Consistent hashing note to deep dive into it.
Cache client and list of servers
How does a cache client know about the available servers in the cache cluster? How do they get an updated list of servers after state change?
For consistent hashing to work reliably, all ache, clients, require the same set of servers? In the absence of it, the same key will be mapped to different servers by different clients. It will lead to inconsistency within the cache system.
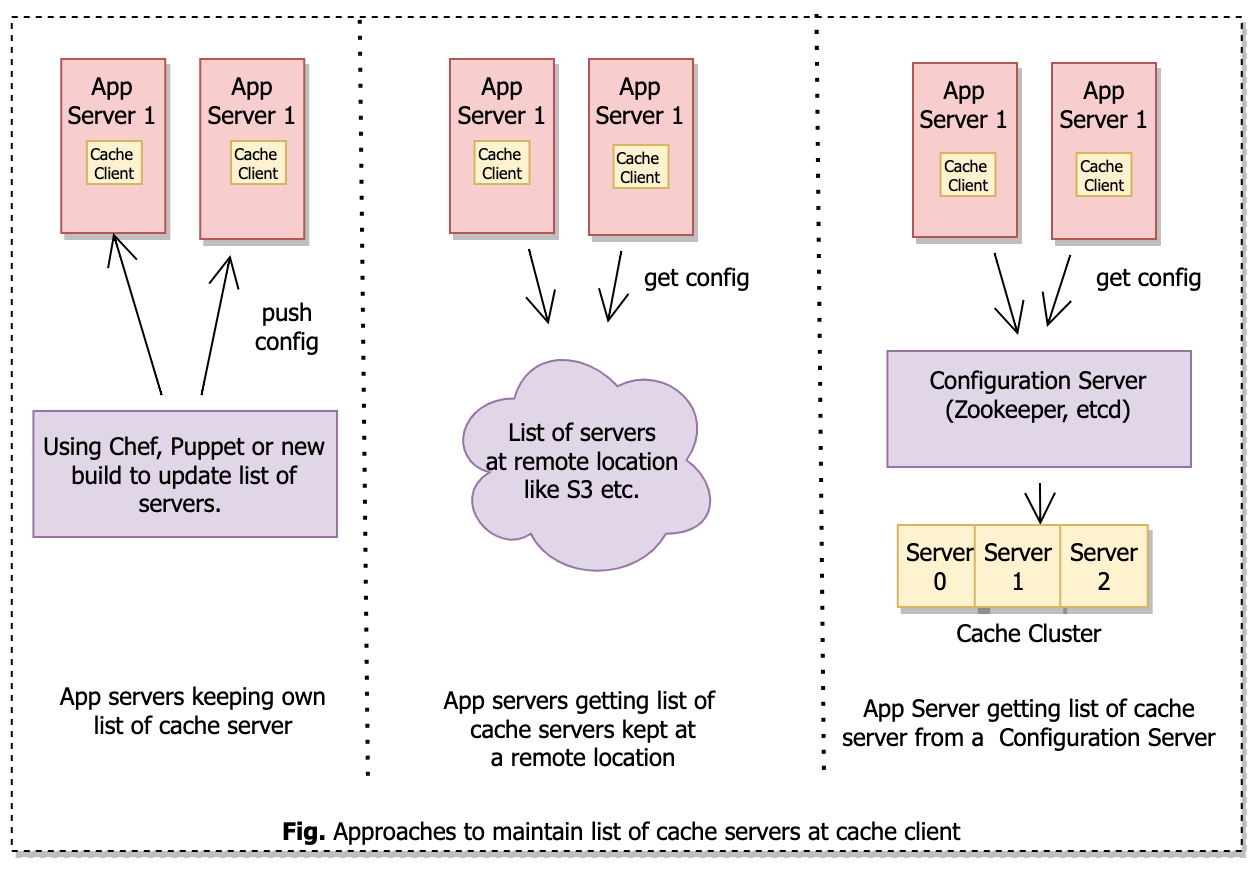
App server keeping gets a list of cache servers from the local file
In this setup, each app server keeps its list of cache servers. When there is a change in the list of cache servers we can use a continuous deployment pipeline to update the list of servers at every app server. We can also use configuration management tools like Chef or Puppet.
Drawbacks of this approach –
- Cache server configuration is static and it requires substantial time to reflect the new changes.
- No guarantee that each app server has the same cache server config at the same time. It can lead to key-to-shard mapping inconsistency.
App server getting a list of cache servers from shared file
In this setup, we can keep the list of cache servers at a shared location like S3 and the app server periodically pulls (using demon) the details of the cache cluster.
This approach is better than the earlier approach and the app server dynamically knows about the active cache servers without redeployment.
The drawback of this approach –
- We need to manually update the list of active cache servers in a shared file.
App server getting a list of cache servers from a configuration service
This is the most exhaustive and expensive approach where we use a configuration server like Apache Zookeeper or Etcd to keep the cache server list. The configuration server automatically keeps track of the availability of the cache server using approach like heartbeat etc.
The app server gets the updated list of cache servers from the configuration server almost instantly.
The drawback of this approach –
- We need to maintain a separate service which is an operational overhead.
We will see further that configuration servers can help in ensuring high availability also.
Requirement checkpoint
Functional requirement –
- Our design accommodates the get and put operation on a cache server.
Non Functional requirement –
- High Performance – Yes high performance is supported, get and put operations are constant time operations and the cache client picks the list of servers in log (n) time. The connection between the cache client and the server is done over TCP / UDP and is also fast.
- Scalability – Yes scalability is supported, shard allows us to accumulate more capacity by adding more shards. To sort hot shard issues we can use consistent hashing to split concrete shards.
- High Availability – No high availability is not there, our system will have lots of cache misses with a single shard getting down due to a crash or network partition (split brain). Our cache cluster is not highly available because of a single point of failure at the shard level.
High Availability
Can we come up with a mechanism which deals with availability and hot shard problem?
Yes, we can use data replication (redundancy) for achieving it.
There are two categories of the data replication protocol
- Favouring eventual consistency – Probabilistic protocols like gossip/epidemic broadcast (P2P), trees, bimodal multicast etc.
- Favouring strong consistency – Consensus protocols such as 2 or 3-phase commit, Paxos, raft, chain replication etc.
Let’s use leader and follower replication for our requirements.
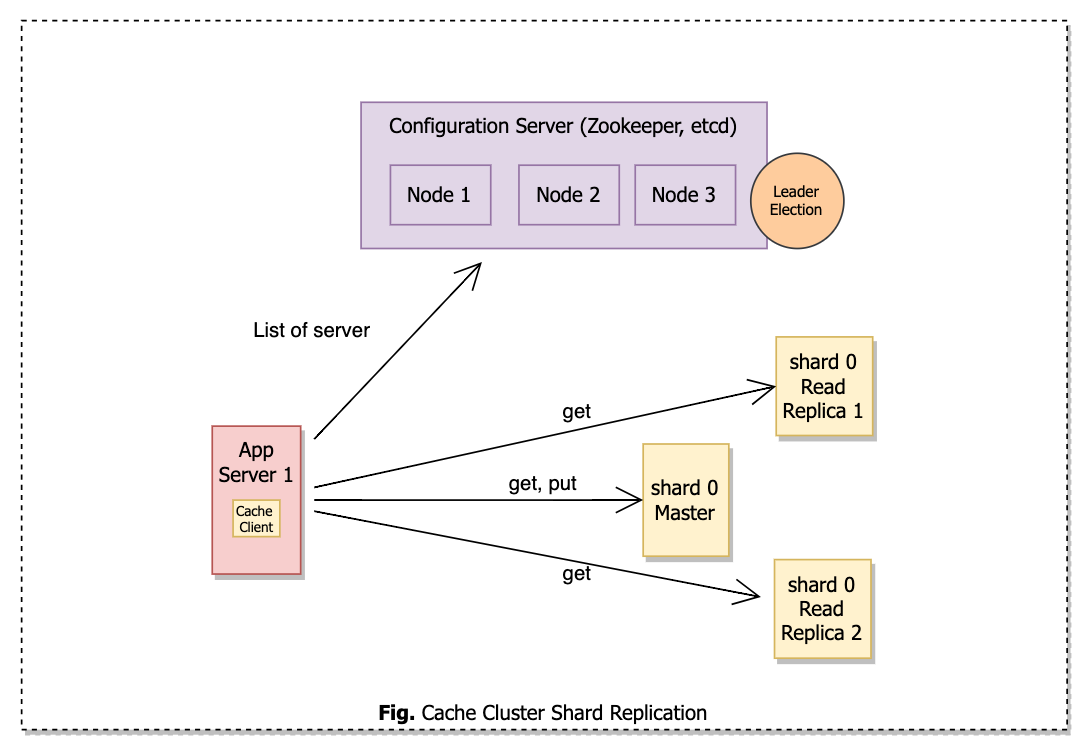
In the above setup, we have one master replica which will handle put as well as get requests, whereas many read replicas will receive get requests.
Many read replicas can help us in solving hot shard problems by allowing us to add more read replicas for specific shards to distribute the load.
The master will replicate data asynchronously with read replicas.
Master and read replicas will communicate with each other over TCP protocol and the replica will automatically connect to the master in case of a network problem.
How is the Leader elected in case the current master fails?
We can use a cache cluster component to promote a follower as a new leader or use a configuration server to act as an authority to decide the leader. We already used a configuration server in our design to keep a list of active cache shards. Hence it will be a good design choice.
Apache Zookeeper, Etcd and Redis Sentinel are a few good choices here.
Did we achieve true high availability?
We achieve good high availability but we didn’t achieve true high availability because our data replication is asynchronous and in case of master failure there is a chance of replicas being out of sync with a small set of data.
This approach is good for performance, as we don’t wait till data gets replicated on all replicas by the master.
This is a good tradeoff and often ok for cache clusters as performance is key to it. In case there is a master failure and there are few key misses, that is acceptable.
Other considerations
Inconsistency
In our design, we can have an inconsistent get operation as data is asynchronously replicated across read replicas. To solve it we will require synchronous replication and we need to evaluate if it is required.
Also, cache clients may have different sets of lists of cache servers leading to inconsistency in the manner data is stored. To solve it we can use a configuration server.
Expiration of stale data
In case the hash table is not full, we will see elements which are no longer used stay in the memory. To make sure we evacuate these elements after a certain period, we can use some metadata like time to live and explicitly clean them by running a job periodically.
Our cache might have billions of data and iterating through them on each run is not feasible, so some probabilistic technique is used to test some items and get going.
Local and Remote Cache
It’s also very common for App servers to use local cache to avoid making calls to distributed cache.
Cache client While creating distributed cache client creates a local cache client too.
Security
Typically they are not optimized for security and tend to run in a secure environment and are accessible by trusted clients using a firewall.
We may encrypt cache data but it will have performance implications and is typically not recommended.
Monitoring & Logging
Adequate logging and monitoring will help in identifying potential performance issues. Its value increases more if we are using distributed cache as a service by many other services.
E.g. Metrics –
- Cache Hits and Misses.
- CPU / Memory utilization on cache servers.
- Network I/O
- Log details of each request to cache.
Cache Client
As we saw, the cache client is doing a lot of work like picking the correct server, making calls, emitting metrics etc. To make the cache client simple we may introduce a cache client proxy between cache client and cache shards. Looking into the twemproxy project by Twitter.
Another strategy is to let a cache server decide which shard to route the request. Clients send requests to any random cache shard and that shard decides where the request will be handled. This strategy is used by Redis Cluster.
Consistent Hashing
Consistent hashing sufferers from two problems and we need to think about them –
- Chain of failures – Let’s say one shard fails and the load transfers to another shard resulting in its loss and failure of another shard and so on.
- Non-uniform distribution of shards on the circle – It’s often that shards are not uniformly placed on the circle resulting in an unbalanced distribution of load.
To solve these problems many approaches are available –
- We can place the same shard multiple times on the circle.
- Jump hashing or proportional hashing.
Summary
First, we implement LRU cache on an app server. To increase the capacity of cache we extended that to run as an independent process on its own cluster or app server cluster as shards. We introduced a cache client which sends the request to the appropriate shard using consistent hashing using the cache key.
We further worked on increasing availability and solving hot shard problems using master-slave replication.
We also introduced a configuration service to provide leader election for shard nodes as well as providing a list of servers to the cache client.
Pingback: A high level intro to rate limiter system and its various components