
Big Data has come a long way. Apache spark is one of the fastest big data computational engines. We will answer often asked questions about the basics of Apache Spark in this article.
What problems Apache Spark solves and how does it solve them?
Big data computation problem
When the size of data is large in terabytes, it is time taking and inefficient to load them into a single machine’s memory and process them for computation. The cost of running a computation on high-end machines (large memory with multiple cores and processors) is very high.
Apache Spark is a cluster-based parallel processing engine that runs efficiently on low-end machines. It can run in-memory as well as on disk.
Limitation in MapReduce processing
MapReduce is a big data-parallel and distributed algorithm to process and generate data set on a cluster. It is the programming model used by Apache Hadoop for big data computation.
MapReduce process everything on disk (cluster of disks) in the following sequential steps.
- Read data from disk
- Map data
- Reduce data
- Write result on disk
IO (Input & Output) from disk takes most of the time of a MapReduce operation. It goes really inefficient when a problem needs multiple iterations on the same data set. We need iterations on the same data set for Graph manipulation, Machine learning algorithms, and other problems.
Apache Spark overcomes the MapReduce big data processing bottlenecks with their in-memory resilient distributed dataset (RDD) data structure, a clustered read-only multi-set of data items. In-Memory it is 100x faster than Apache Hadoop MapReduce, while on the disk it is 10x faster.
With RDDs implementation now it is possible to use iterative algorithms which use the same dataset in a loop as well as repeated database-style querying.
The complex big data ecosystem
Apache Hadoop, another big data computation platform grown as the complex ecosystem of tools and libraries for solving real-time streaming, structured data analysis, machine learning, etc. Usually, development has to opt for newer frameworks leads to increased cost of maintenance.
Apache Spark provides a unified ecosystem with low-end API along with high-level APIs and tools for real-time streaming, machine learning, etc.
What are the various components of Apache Spark?
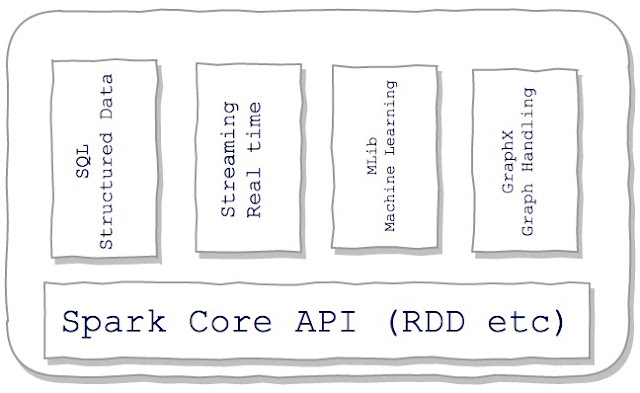
Apache Spark Various Components
Spark Core – Apache Spark core includes RDD (Resilient Distributed Dataset) API, Cluster management, scheduling, data source handling, memory management, fault tolerance, and others functionalities. Apache Spark’s general-purpose fast computational core provides fundamentals for building higher-level API for various purposes. The benefits of tightly coupled architecture are that when Core get improvements, further high-level API also get benefitted.
Spark SQL, DataFrames, and Datasets – It provides API for processing structured data (JSON, relational database, and others). You can query the dataset using SQL-like syntax.
Spark Streaming – It provides API for processing real-time streams of data coming from various sources like Kafka, Flume, Kinesis, or TCP sockets. These real-time streams can be further processed using complex machine learning, graph, and other algorithms.
Spark MLib (Machine Learning) – It provides API for executing Machine Learning algorithms like Classification, Regression, Collaborative Filtering, and others.
Spark GraphX – It provides API for doing parallel computation on Graph data (e.g Facebook friend graph). It also gives inbuilt support for Graph algorithms like Page Rank and Triangle counting.
In which programming languages you can write Spark applications?

Apache Spark Programming Language Supports
Apache Spark provides libraries and tools for writing an application using Scala, Java, Python, and R programming languages.
You can also interact with Apache Spark with Scala Python and R CLI (Command Line Interface) to execute exploratory queries. It helps Data Scientists a lot.
How Apache Spark application execute?

The lifecycle for Spark program execution on the cluster:
- You write Spark applications, package them and send them to the main spark server (not Worker Node). In your application’s main program (Driver Program) you use SparkContext. Spark application runs on a cluster as an independent process coordinated by SparkContext.
- SparkContext can connect to worker nodes using many Cluster Managers.
- SparkContext acquires worker node executor process. These processes run computations and store data for the app.
- SparkContext sends application code (JARs or Python files) to the executor node.
- SparkContext send tasks to the worker node executor for further process.
A few special features of a Spark application architecture are:
- Each application is given its executor process. The executor process stays up until the end of the program and executes it in multiple threads. It brings isolation between multiple Spark applications. Data sharing between nodes are also not possible without writing them on disk.
- Spark can work with any Cluster Manager as long as they can acquire executor processes on the node.
- The network connection between the worker node and the driver program is a must.
- Keeping driver program and worker node close to each other (preferably on the same LAN) decreases the latency of cluster task scheduling.
What data storage Apache Spark supports?
Apache Spark doesn’t have its own data storage capabilities. Though it supports several data storages like Hadoop Distributed File System (HDFS), HBase, Cassandra, Apache Hive, Amazon S3, and others. It has options to add custom data backend.
Which cluster managers Apache Spark supports?
Apache Spark comes with its native cluster manager, which is good for small deployment. Though it can also use Hadoop YARN and Apache Mesos as its cluster manager.
Why Apache Hadoop bundle with Apache Spark distribution?
Apache Spark gives support for Hadoop YARN and Mesos cluster manager. Apache Spark depends on Hadoop client libraries for YARN and Mesos. We may download Spark build without the Hadoop bundle. We can also refer to the existing installation of Hadoop if it is on the same machine as Apache Spark.
References
- Apache Spark latest documentation (Click Here)
- MapReduce framework Wikipedia article (Click here)
- Apache Hadoop Ecosystem
- Apache Spark Wikipedia article (Click Here)
- MapReduce algorithm Wikipedia article
- Hadoop YARN official website
- Apache Mesos official website